به یک مقاله جالب برخوردم به نام «روش علمی گوگل». اول به نظرم رسید دربارهی گوگل است و اتفاقا چند مثال هم از گوگل دارد، ولی به کمک مثالها به مفهومی فراتر از گوگل میرسد که بسیار جالب و خواندنی است.
قسمتهایی از آنرا ترجمهی آزاد کردم ولی اگر به موضوع علاقهمند شدید اصل آن را از دست ندهید که مفصلتر است.
گروهی بر این باورند که با ظهور بانکهای اطلاعاتی خیلی خیلی بزرگ، شیوهی یادگیری ما (به عنوان نوع انسان) کاملا دگرگون میشود. روش علمی کلاسیک بر اساس ساخت فرضیه و مدلی که رویدادهای تجربی را توصیف کند، پایهگذاری شده است. اما ما اکنون به اندازهی کافی داده از مشاهداتمان داریم که بتوانیم بدون اینکه مدل یا فرضیهای داشته باشیم، رویدادها یا مشاهدات بعدی را پیشبینی کنیم (کاری که علم انجام میدهد: قدرت پیشبینی).
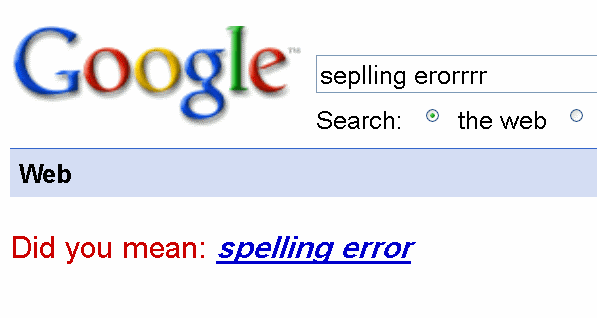
غلطگیر املایی گوگل
وقتی در گوگل جستجو میکنید گوگل غلطهای املایی شما را در نوشتن کلیدواژهها اصلاح میکند و به شما پیشنهاداتی میدهد. گوگل برای اینکار از هیچ تئوری یا مدلی که قوانین درست نوشتن را شرح دهد استفاده نمیکند. به جای آن، گوگل روی مجموعهی بزرگی از داده کار میکند که متشکل از عبارتهایی مانند این است: «x نفر به این سئوال که آیا منظورتان y بود پاسخ بله دادهاند» استفاده میکند. این الگورتیم هیچ تصوری از املای صحیح لغتها در زبان انگلیسی ندارد و فقط به آمار مراجعه میکند و میتواند غلطهای املایی را در همهی زبانها اصلاح کند (به شرطی که داده به اندازهی کافی به آن زبان وجود داشته باشد).
ابزار ترجمهی گوگل
گوگل از فلسفهی مشابهی برای ترجمه از یک زبان به زبان دیگر استفاده میکند. ابزار ترجمهی گوگل میتواند متنهای آلمانی را به چینی یا انگلیسی را به فرانسوی ترجمه کند و اینکار را با تطبیقدهی «عبارت شما» با مجموعههای عظیم ترجمههایی که توسط انسان انجام شده انجام میدهد. برای نمونه، گوگل موتور ترجمهی انگلیسی/فرانسوی خود را با تغذیهی متنهای کانادایی که معمولا دوزبانه هستند تربیت کرده است. گوگلیها برای اینکار از هیچ تئوری نحوی زبانی یا الگوریتم هوش مصنوعی استفاده نکردهاند. آنها فقط میلیاردها «نکته» و «لینک» دارند که میگوید «این آن است» یا به عبارتی «این» در زبان اول «آن» در زبان دوم است. آقای پیتر نورویگ رئیس بخش تحقیقات گوگل با اشارهی پنهان به تجربهی فکری اتاق چینی در نظریهی هوش مصنوعی میگوید:
هیچیک از اعضای تیمی که روی موتور ترجمهی چینی گوگل کار میکردند، چینی صحبت نمیکرد.
![]()
دانش بدون نظریه
اگر میشود بدون دانستن حتی یک کلمه انگلیسی، غلطهای املایی عبارتهای نوشته شدهی انگلیسی را گرفت، یا اگر میشود بدون دانستن حتی یک کلمه چینی، متون انگلیسی را به چینی ترجمه کرد، سئوالی که مطرح میشود این است که دیگر چه چیزهایی را میتوان بدون داشتن فرضیه یا مدل دریافت؟
آقای کریسآندرسن در وایرد (Wired) مینویسد:
به کمک ریاضیات کاربردی و با داشتن میزان به اندازهی کافی بزرگ داده (data) از رفتار انسانهای مختلف، میتوانیم با دقت کافی رفتار آدمها را پیشبینی کنیم. کسی چه میداند چرا افراد اینگونه رفتار میکنند، مهم این است که اینکارها را میکنند و ما میتوانیم آنرا پیشبینی کنیم (معادل اینکه بگوییم: برای چه کسی مهم است که من چینی نمیدانم یا میدانم، مهم این است که من به اندازهی کافی داده دارم که حدس بزنم ترجمهی این عبارت به چینی چه میشود).
پتابایتهای (هزاران ترابایت) داده کافی هستند که بگوییم هبستگی (correlation) کافی است. میتوانیم به کمک الگوریتمهای آماری و محاسبهی خوشهای (cluster computing)، حجم بسیار بزرگی از داده را تحلیل کنیم و نتایج کاربردی و مفید بگیریم، بدون اینکه فرضیهای داشته باشیم که به ما بگوید اینها چه معنایی دارند.
دانشمندان علوم مختلف مانند اخترشناسی، فیزیک، ژنتیک، زبانشناسی و زمینشناسی در حال گردآوری و تولید پیوستهی داده هستند که حجم آن امروز به پتابایتها میرسد و در کمتر از یک دههی دیگر به سطح اکسابایت (exabyte = 1000 petabyte) خواهد رسید. به کمک روشهای «یادگیری ماشین» (Machine Learning) ماشینها میتوانند از این دریای اطلاعات الگوهایی استخراج کنند که هیچ انسانی هرگز نمیتواند کشف کند. اینها الگوهای هبستگی هستند و ممکن است سببی (Causative) باشند یا نباشند، اما به کمک آنها میتوانیم چیزهای جدید یاد بگیریم. بنابراین آنها کاری را که علم انجام میدهد انجام میدهند؛ اگرچه نه به شیوهی سنتی.
همیشه اگر همبستگی به اندازهی کافی باشد قابل قبول است. بخش بزرگی از علم پزشکی اینگونه پیشرفت کرده. پزشک شاید نداند علت اصلی بروز خیلی از بیماریها چیست، اما میتواند نشانههای آن را تشخیص دهد و مسیر بیماری را پیشبینی کند. در واقع مدل درمانی او بر اساس همبستگی تعداد زیادی بیماری با خصوصیات مشابه شکل گرفته است.
نکتهی مهم این است که این روش در حال ظهور به یک ابزار جدید در «روش علمی» تبدیل میشود و قرار نیست جایگزین آن شود.
در همینرابطه:
- تجربهی فکری بحثبرانگیز اتاق چینی – قسمت اول
- تجربهی فکری اتاق چینی – قسمت دوم
- کارگاه گوگل دربارهی آموزش Data Intensive Scalable Computing
مشترک خوراک بامدادی شوید
کامل
فقط مطالب
فقط لینکدونی

مبحث بسیار جالبی بود ممنون . اما نمی دونم چرا ناخود آگاه در مورد روشهای جدید نوعی ترس دارم . فکر می کنم شبیه کشیشهای قرون وسطا شده ام
لایکلایک
اين نظريه اي كه مطرح كردي سنگ بناي علم هوش مصنوعيه. اگر به تركيب «هوش مصنوعي» (
Artificial Intelligence ) توجه كني, همين مفهوم رو ميرسونه، ولي مهم اينه كه اين ديتابيس و ايندكس بايد ابتدا توسط يك دانش با نظريه پر بشه. حتي در مورد همون زبان چيني. به هر حال هوش مصنوعي براي من هميشه از جذاب ترين موضوعات علمي بوده.
لایکلایک
یه مقاله مرتبط با این خوندم که الان لینکش رو یادم نیست
عنوانش این بود:
Is Google Making us Stupid?
لایکلایک
خیلی جالب بود. یعنی روزی خواهد رسید که انسان هم از این طریق بتواند تحلیل کند؟ چون ما حجم وسیعی از مغزمان را استفاده نمی کنیم و شاید آن حجم عظیم جای چنین اطلاعاتی باشند!
لایکلایک
جالب بود فقط توجه داشته باش که مدل استفاده از تئوری حالتهایی را هم که هنوز اتفاق نیفتاده را نیز پیش بینی میکند و یا به آنها اعتبار میبخشد (مثلا دستور زبان جملاتی که تا به حال کسی نگفته را اعتبار میبخشد)
لایکلایک
بامدادیی عزیز،
ممنون از این خلاصهای که قرار دادید.
چیزی که برایام نگرانکننده است کنار هم قرار دادن تکههایی است که به هم ربط ندارند. این مقاله ادعاهایی میکند که کم و بیش (ولی نه کاملا) درستاند، اما وقتی همهشان را کنار هم میگذارد به نتایج نادقیقای میرسد.
بیاید مهمترین ادعای این مقاله را بررسی کنیم:
«روش علمی کلاسیک بر اساس ساخت فرضیه و مدلی که رویدادهای تجربی را توصیف کند، پایهگذاری شده است. اما ما اکنون به اندازهی کافی داده از مشاهداتمان داریم که بتوانیم بدون اینکه مدل یا فرضیهای داشته باشیم، رویدادها یا مشاهدات بعدی را پیشبینی کنیم»
این حرف صحیح نیست.
اول از همه چیزی که این مقاله به اسم روش علمیی کلاسیک میشناسد نیز نیاز به داده دارد تا میزان صحتاش با احتمالای مشخص شود (و نه اثبات شود).
نکتهی دوم این است که بدون فرضیهای اولیه هیچگونه استدلال بعدیای ممکن نیست. حتی اگر بینهایت داده نیز داشته باشیم، بدون داشتن «فرضیه» در مورد پدیدهی تولیدکنندهی این دادهها نمیتوان پیشبینیای انجام داد. اینکه میبینیم خیلی وقتها به نظر میرسد که چنین فرضیهای وجود ندارد به این دلیل است که این فرضیه را به صورت بارز (explicit) بیان نکردهایم و به جایاش فرضیهمان به صورت ضمنی (implicit) جایی قرار گرفته است (و گاهی متاسفانه خودِ دادهکاو نیز از وجود فرضیه ناآگاه است).
تفاوت تنها در میزان قوت و وزنای است که روی فرضیهی اولیه میگذاریم. گاهی این فرضیه بسیار قوی است و دادهها تنها قرار است بعضی از ناشناختههای آن فرضیه را تبیین کنند، گاهی فرضیهی اولیه حداقلی است و بسیاری از ناشناختهها (اما نه همه چیز) به کمک دادهها مشخص میشوند.
لایکلایک
جالب بود.ایول
لایکلایک
@صندوقک:
ترس هم داره. در مورد تکینگی تکنولوژیک و این نظریه که ممکنه انسان از دانش تولید شده توسط محصولات خودش عقب بمونه شاید بنویسم.
@نگاه:
به مفهوم هوش مصنوعی مرتبطه، ولی این دو مقوله با هم یکی نیستند. بحث اتاق چینی البته ماهیت هوش رو به شکل بینظیری به پرسش میگیره که هنوز که هنوزه پاسخ مناسبی براش پیدا نشده.
@صادق:
ظاهرا مسیر به سویی میرود که از آن بخش کوچک مغزمان هم کمتر استفاده کنیم!
لایکلایک
@شهریار:
بله درسته، به کمک مدل با دادههای نسبتا اندک میتونیم قدرت پیشبینی نسبتا زیادی به دست بیاریم. اما در مواقعی که مدلسازی ناممکن یا بسیار پیچیده هست، روش تولید دانش بدون استفاده از مدل میتونه کارساز باشه.
لایکلایک
@سولوژن:
اول ممنون از کامنت خوبت.
قبول دارم که نوشته مبحث هوش مصنوعی و اتاق چینی را به گونهی نه چندان مستدلی به «روش علمی» و «رابطهی بین مدل انتزاعی و تجربهی عینی» ربط داده.
ولی بیا موضوع را از دید دیگری نگاه کنیم. در واقع اجازه بده برگردیم به اتاق چینی و مثالهایی که در خود نوشته آمده از گوگل.
در اینجا بحث اصلی این نیست که آیا مدل وجود دارد یا نه، داده وجود دارد یا نه. به نظرم اختلاف اصلی این است که با استفاده از مدلهای کاملا ریاضی که هیچ ربطی به آن پدیدهی تجربی و عینی بیرونی ندارند، بیاییم و رفتار یا خصوصیتهای آن پدیده را پیشبینی کنیم. یعنی مدل ما دربارهی آن پدیده نباشد، و صرفا یک مدل انتزاعی باشد.
اگر من با استفاه از «مدلی نحوی از زبان انگلیسی» و «مجموعهی محدود واجها و واژههای یک زبان» شروع به اصلاح عبارتهای انگلیسی کنم، موضوع فرق میکند تا اینکه با استفاده از یک مدل صرفا آماری و با مراجعه به تعدادی بیشماری (از نظر فیزیکی بیشمار) نمونه از جملههای انگلیسی این کار انجام دهم. بدون اینکه مدل من هیچ تصوری از زبان انگلیسی داشته باشد. شاید بشود به نوعی گفت، مدل اول (نحوی) به سوژهاش آگاه است ولی در حالت دوم، مدل من به سوژهاش آگاه نیست.
اگر خیلی این موضوع را موشکافی کنیم، در دل آن به همان تجربهی اتاق چینی خواهیم رسید که برایش جوابی هم وجود ندارد. موضوع خیلی پیچیده میشود و از حالت عملی خارج و به یک تجربهی ذهنی تبدیل میشود که در نوع خود همیشه جالب است.
لایکلایک
عالی بود بامداد عزیز.
لایکلایک
من تصورم این بود که بحثِ اصلی این است که آیا «دانش بدون نظریه» معنادار است یا نه.
حال در بحث جدیدی که مطرح کردید این سوال برایام پیش میآید: آیا تفاوت تنها در این نیست که انتزاع مدلها گاهی توسط انسان انجام میشود و گاهی توسط ماشین؟
لایکلایک
@سولوژن:
به معنای عام حرفت کاملا درسته. به نظر من دانش بدون نظریه بیمعناست. بالاخره باید یک دستگاه منطقی وجود داشته باشه که بر اساس اون آمار گردآوری بشه.
این سئوالیه که هنوز بهش پاسخ درستی داده نشده. هوش چیه و چه چیز ما رو از اون کامپیوتر متمایز میکنه.
بحث به نظر من همون میزان انتزاعی بودن مدل هست و همونطور که گفتم اگه موضوع رو خیلی موشکافی کنیم، به بنبستی میرسیم که اتاق چینی میرسه. همیشه در یک سطحی انتزاع وجود داره و مدل از واقعیت فاصله میگیره (یعنی دیگه فقط یک ابزار ریاضی میشه) حتی تجربیترین مدلها.
لایکلایک
بامدادی عزیز! فکر کنم هر دویمان حرفهایمان را زدیم. بحث جالبای بود.
لایکلایک
khyli khob bod .mamnonam.
لایکلایک
مقاله فوق ایده طراحی عامل های هوشمنده که درطراحی عامل های هوشمند تمامی ادراکات به پایگاه دانش اضافه می شه و عامل هوشمند برای پیدا کردن عملکرد بهینه ، با استفاده از قوانین منطقی استدلال می کنه.. همونطور که گفتی مدل وجود نداره ولی قوانین بسیار قوی ای برای جستجو طراحی میشه.
بحثی است بسیار گسترده و شیرین..
ممنون از یادآوری و تجدید یک سری مطالعات قدیمی ام تو این زمینه از گذشته.
«بامدادی» تو هر زمینه ای سخن خوب برای خوندن داره!!!
🙂
———————————————————————
بامدادی: بله، در واقع مدل وجود داره. اما شاید بشه گفت پیچیدگی مدل از پیچیدگی نتایجی که تولید میکنه خیلی کمتره..
لایکلایک